

What is cloud Data Fusion?
Comprehensive Guide to Cloud Data Fusion in GCP
Introduction to Cloud Data Fusion
Cloud Data Fusion is a fully managed, cloud-native data integration service offered by Google Cloud Platform (GCP). Designed to streamline the creation of data pipelines, Cloud Data Fusion allows organizations to seamlessly integrate disparate data sources, enabling real-time or batch processing. It is built on the open-source CDAP (Cask Data Application Platform) and provides a visual interface for users to design, deploy, and monitor data pipelines without requiring deep coding expertise.
This article explores the features, architecture, and benefits of Cloud Data Fusion, provides a comparison with its closest competitor services, and includes GCP CLI commands to create a Cloud Data Fusion instance.
Key Features of Cloud Data Fusion
- Visual Pipeline Design:
- A drag-and-drop interface allows users to build complex ETL/ELT pipelines easily.
- Pre-built connectors and transformations simplify common data integration tasks.
- Built-in Security and Compliance:
- Tight integration with Google Cloud IAM ensures secure access control.
- Support for encrypted data processing and audit logs helps meet compliance requirements.
- Real-time and Batch Processing:
- Offers flexibility to execute pipelines in batch mode or stream mode.
- Extensive Connectivity:
- Supports connections to a variety of data sources such as BigQuery, Cloud Spanner, MySQL, PostgreSQL, Oracle, SaaS applications, and on-premises data systems.
- Operational Monitoring:
- Users can monitor pipeline performance, debug issues, and analyze logs using built-in tools.
- Open-source Ecosystem:
- Being built on CDAP, users benefit from a large developer community and access to open-source plugins.
Cloud Data Fusion Architecture
Cloud Data Fusion is a hybrid architecture that supports both cloud and on-premises systems. The architecture is comprised of the following components:
- Pipelines:
- A sequence of transformations, filters, and aggregations applied to the data.
- Plugins:
- Extend functionality to work with custom data sources, transformations, or sinks.
- Data Pipeline Runtimes:
- Executes data pipelines on Google Kubernetes Engine (GKE) or other environments.
- Control Plane and Data Plane:
- The control plane handles pipeline design and monitoring, while the data plane manages pipeline execution.
Creating a Cloud Data Fusion Instance Using GCP CLI
To create a Cloud Data Fusion instance in the GCP portal, follow these steps using the GCP CLI:
# Step 1: Set your GCP project
gcloud config set project [PROJECT_ID]
# Step 2: Define the region for your Cloud Data Fusion instance
REGION=[REGION] # Example: us-central1
# Step 3: Define the name for the Cloud Data Fusion instance
INSTANCE_NAME=[INSTANCE_NAME] # Example: my-data-fusion-instance
# Step 4: Create the Cloud Data Fusion instance
gcloud data-fusion instances create $INSTANCE_NAME \
–location=$REGION \
–type=developer \
–enable-stackdriver-logging \
–enable-stackdriver-monitoring \
–labels=env=development,team=data-engineering
# Step 5: Verify the instance creation
gcloud data-fusion instances describe $INSTANCE_NAME –location=$REGION
# Step 6: Connect to the instance via the GCP console or CLI
echo “Access the instance at: https://$REGION.datafusion.googleusercontent.com/$INSTANCE_NAME”
Notes:
- Replace
[PROJECT_ID],[REGION], and[INSTANCE_NAME]with appropriate values for your project. - The
--typeflag specifies the instance type (developer,basic, orenterprise). For testing and small-scale pipelines, usedeveloper.
Benefits of Using Cloud Data Fusion
- Simplifies Data Integration:
- With its intuitive interface, Cloud Data Fusion makes it easier for data engineers and analysts to build and deploy pipelines.
- Cost Efficiency:
- Eliminates the need for complex infrastructure setup and reduces operational overhead.
- Scalability:
- Seamlessly scales to handle large datasets or complex pipelines.
- Enhanced Collaboration:
- Role-based access control allows multiple teams to work collaboratively on data projects.
- Tight Integration with GCP Services:
- Leverages the power of BigQuery, Cloud Storage, and other GCP tools for analytics and storage.

Common Use Cases
- Data Migration:
- Migrate on-premises databases or files to Google Cloud services like BigQuery or Cloud SQL.
- Data Lakes and Warehouses:
- Consolidate raw data into a centralized repository for analytics and machine learning.
- Real-time Analytics:
- Stream data from IoT devices or logs for real-time processing and insights.
- ETL/ELT Workflows:
- Perform transformations and load data into destinations like BigQuery or Cloud Spanner.
- Data Enrichment:
- Augment datasets with additional contextual data from APIs or third-party sources.
Challenges and Best Practices
Challenges:
- Learning Curve:
- For teams unfamiliar with CDAP, there might be a learning curve.
- Latency in Real-time Pipelines:
- Stream processing may introduce latency depending on the complexity of transformations.
Best Practices:
- Use the Right Instance Type:
- Choose the
developer,basic, orenterprisetype based on the use case and expected load.
- Choose the
- Leverage Pre-built Plugins:
- Use the CDAP marketplace to speed up pipeline development.
- Optimize Pipeline Design:
- Avoid unnecessary transformations to reduce pipeline latency and cost.
- Enable Logging and Monitoring:
- Always enable Stackdriver for effective monitoring and debugging.
Conclusion
Google Cloud Data Fusion offers a powerful, flexible, and user-friendly solution for managing complex data integration workflows. With its strong emphasis on simplicity and scalability, it caters to the needs of organizations looking to modernize their data processing infrastructure. By leveraging its seamless integration with the GCP ecosystem and open-source extensibility, businesses can unlock new insights and achieve operational efficiency.
Cloud Data Fusion stands out with its combination of real-time capabilities, robust security, and visual design tools, making it an ideal choice for both novice and experienced data professionals.
FAQs
- What is Cloud Data Fusion, and how does it work?
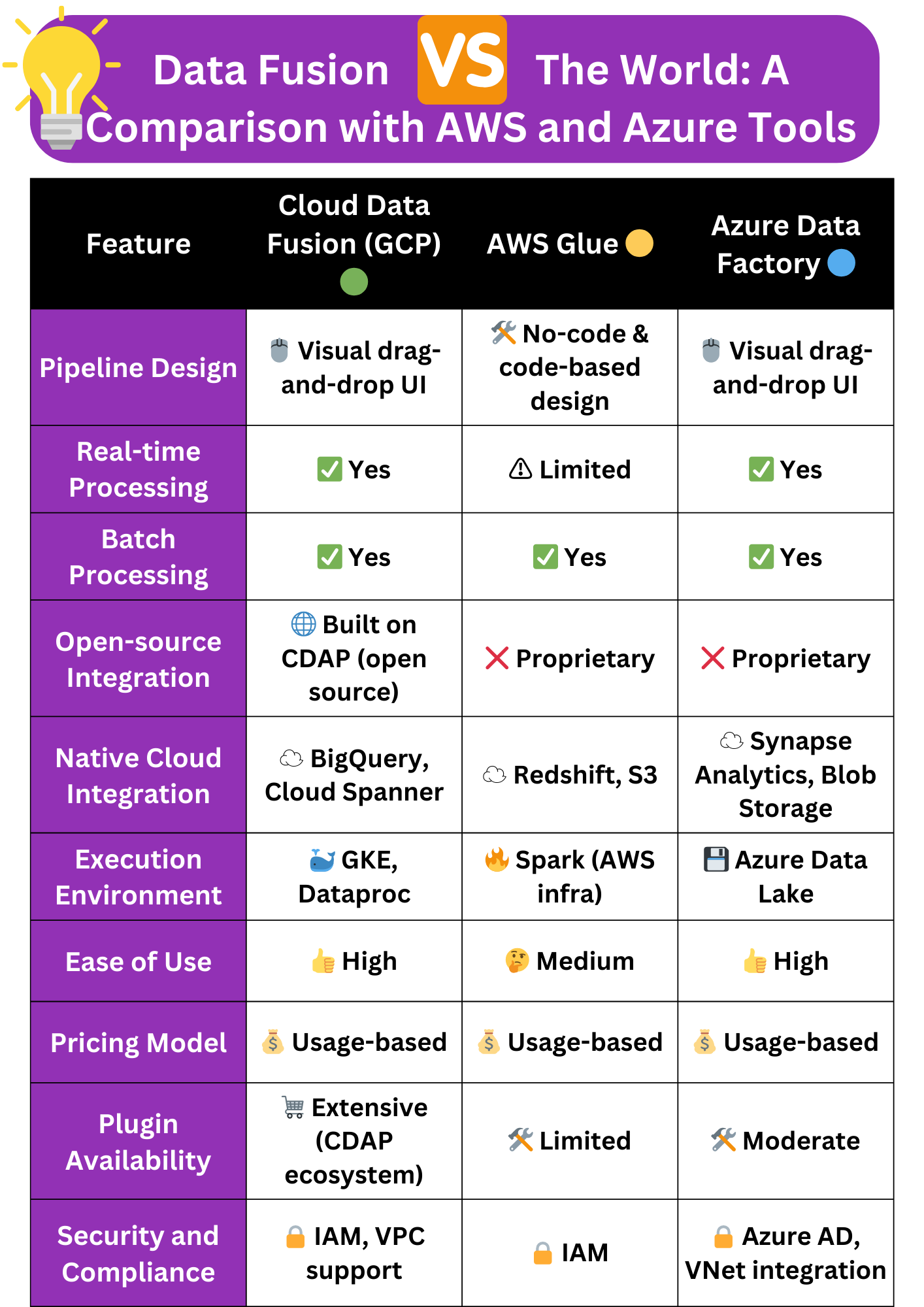
Cloud Data Fusion is a fully managed, cloud-native data integration tool on GCP. It uses a visual interface to design ETL/ELT pipelines for batch and real-time processing. - How does Cloud Data Fusion compare with AWS Glue and Azure Data Factory?
Key differences lie in their integration capabilities, open-source support (CDAP in Data Fusion), and ease of use through visual UI. Azure and AWS focus more on proprietary ecosystems. - What are the common use cases for Cloud Data Fusion?
Popular use cases include building data pipelines for BigQuery, IoT data ingestion, real-time analytics, and batch processing. - Can Cloud Data Fusion handle real-time data streaming?
Yes, Cloud Data Fusion supports real-time data streaming with integrations like Pub/Sub and Kafka. - What are the pricing models of Cloud Data Fusion compared to its competitors?
Cloud Data Fusion follows a usage-based pricing model, similar to AWS Glue and Azure Data Factory, but specifics depend on job runtimes and resource usage. - How secure is Cloud Data Fusion?
It ensures security using GCP’s IAM policies, VPC support, and encryption for data in transit and at rest.

Cybersecurity Architect | Cloud-Native Defense | AI/ML Security | DevSecOps
𝐖𝐢𝐭𝐡 𝟐𝟑+ 𝐲𝐞𝐚𝐫𝐬 𝐨𝐟 𝐞𝐱𝐩𝐞𝐫𝐭𝐢𝐬𝐞 𝐢𝐧 𝐜𝐲𝐛𝐞𝐫𝐬𝐞𝐜𝐮𝐫𝐢𝐭𝐲 𝐚𝐧𝐝 𝐜𝐥𝐨𝐮𝐝-𝐧𝐚𝐭𝐢𝐯𝐞 𝐝𝐞𝐟𝐞𝐧𝐬𝐞, 𝐈 𝐚𝐫𝐜𝐡𝐢𝐭𝐞𝐜𝐭 𝐫𝐞𝐬𝐢𝐥𝐢𝐞𝐧𝐭 𝐝𝐢𝐠𝐢𝐭𝐚𝐥 𝐞𝐜𝐨𝐬𝐲𝐬𝐭𝐞𝐦𝐬 𝐛𝐲 𝐢𝐧𝐭𝐞𝐠𝐫𝐚𝐭𝐢𝐧𝐠 𝐙𝐞𝐫𝐨 𝐓𝐫𝐮𝐬𝐭, 𝐭𝐡𝐫𝐞𝐚𝐭 𝐢𝐧𝐭𝐞𝐥𝐥𝐢𝐠𝐞𝐧𝐜𝐞, 𝐚𝐧𝐝 𝐩𝐫𝐨𝐚𝐜𝐭𝐢𝐯𝐞 𝐫𝐢𝐬𝐤 𝐦𝐢𝐭𝐢𝐠𝐚𝐭𝐢𝐨𝐧 𝐢𝐧𝐭𝐨 𝐞𝐯𝐞𝐫𝐲 𝐥𝐚𝐲𝐞𝐫 𝐨𝐟 𝐢𝐧𝐟𝐫𝐚𝐬𝐭𝐫𝐮𝐜𝐭𝐮𝐫𝐞.
My journey began in network security (firewalls, IDS/IPS) and evolved through Linux/Windows hardening, IAM, and DevSecOps—bridging security with agile development. Today, I specialize in securing multi-cloud (AWS/Azure/GCP) environments.
𝐀𝐬 𝐚 𝐭𝐫𝐮𝐬𝐭𝐞𝐝 𝐚𝐝𝐯𝐢𝐬𝐨𝐫, 𝐈 𝐡𝐞𝐥𝐩 𝐨𝐫𝐠𝐚𝐧𝐢𝐳𝐚𝐭𝐢𝐨𝐧𝐬:
✔️ Align security investments with business objectives (reducing TCO while maximizing cyber ROI).
✔️ Prioritize risks executives care about—translating technical vulnerabilities into financial/operational impact.
✔️ Optimize team workflows by merging DevSecOps agility with governance rigor—no more “security vs. speed” trade-offs.
𝐂𝐨𝐫𝐞 𝐒𝐭𝐫𝐞𝐧𝐠𝐭𝐡𝐬 & 𝐃𝐢𝐟𝐟𝐞𝐫𝐞𝐧𝐭𝐢𝐚𝐭𝐢𝐨𝐧:
𝘌𝘯𝘥-𝘵𝘰-𝘦𝘯𝘥 𝘴𝘦𝘤𝘶𝘳𝘪𝘵𝘺 𝘢𝘳𝘤𝘩𝘪𝘵𝘦𝘤𝘵𝘶𝘳𝘦—𝘧𝘳𝘰𝘮 𝘯𝘦𝘵𝘸𝘰𝘳𝘬 𝘩𝘢𝘳𝘥𝘦𝘯𝘪𝘯𝘨 𝘵𝘰 𝘈𝘐-𝘥𝘳𝘪𝘷𝘦𝘯 𝘵𝘩𝘳𝘦𝘢𝘵 𝘥𝘦𝘵𝘦𝘤𝘵𝘪𝘰𝘯.
𝐌𝐮𝐥𝐭𝐢-𝐂𝐥𝐨𝐮𝐝 𝐒𝐞𝐜𝐮𝐫𝐢𝐭𝐲: Deep expertise in AWS/Azure/GCP security tools (Kubernetes, CSPM, CWPP).
𝐓𝐡𝐫𝐞𝐚𝐭 𝐈𝐧𝐭𝐞𝐥𝐥𝐢𝐠𝐞𝐧𝐜𝐞 & 𝐅𝐨𝐫𝐞𝐧𝐬𝐢𝐜𝐬: Proactive hunting, incident response, and post-breach analysis.
𝐙𝐞𝐫𝐨 𝐓𝐫𝐮𝐬𝐭 & 𝐈𝐀𝐌: Architecting least-privilege access, PKI, and micro-segmentation.
𝐀𝐈/𝐌𝐋 𝐒𝐞𝐜𝐮𝐫𝐢𝐭𝐲: Securing LLMs, MLOps pipelines, and data lakes against adversarial attacks.
𝐑𝐞𝐜𝐞𝐧𝐭 𝐂𝐨𝐧𝐬𝐮𝐥𝐭𝐢𝐧𝐠 𝐏𝐫𝐨𝐣𝐞𝐜𝐭𝐬 – 𝐀𝐠𝐞𝐧𝐭𝐢𝐜 𝐀𝐈 & 𝐀𝐈 𝐒𝐞𝐜𝐮𝐫𝐢𝐭𝐲:
✔️ Led security architecture for a GenAI‑powered Agentic AI system (autonomous task‑planning agents using LangChain & AutoGPT). Designed guardrails against prompt injection, tool‑calling abuse, and data exfiltration via agent‑to‑agent communication. Result: Zero security breaches across 10k+ agentic transactions.
✔️ Advised a fintech firm on AI supply chain security – hardened their LLM fine‑tuning pipeline (Hugging Face + AWS SageMaker) against model poisoning and backdoor attacks. Implemented real‑time anomaly detection for model inputs using statistical outlier scoring.
Let’s connect and discuss the future of secure, intelligent infrastructure.